JFreq
Count words, quickly
JFreq takes plain text documents and turns them into a word frequency matrix. It tries hard to be a) quick, and b) not take up much memory. It could be better at both, but it’s quite usable. The graphical version looks like this on a Mac with the online help open. Click on the image to see it full size in a new browser window.
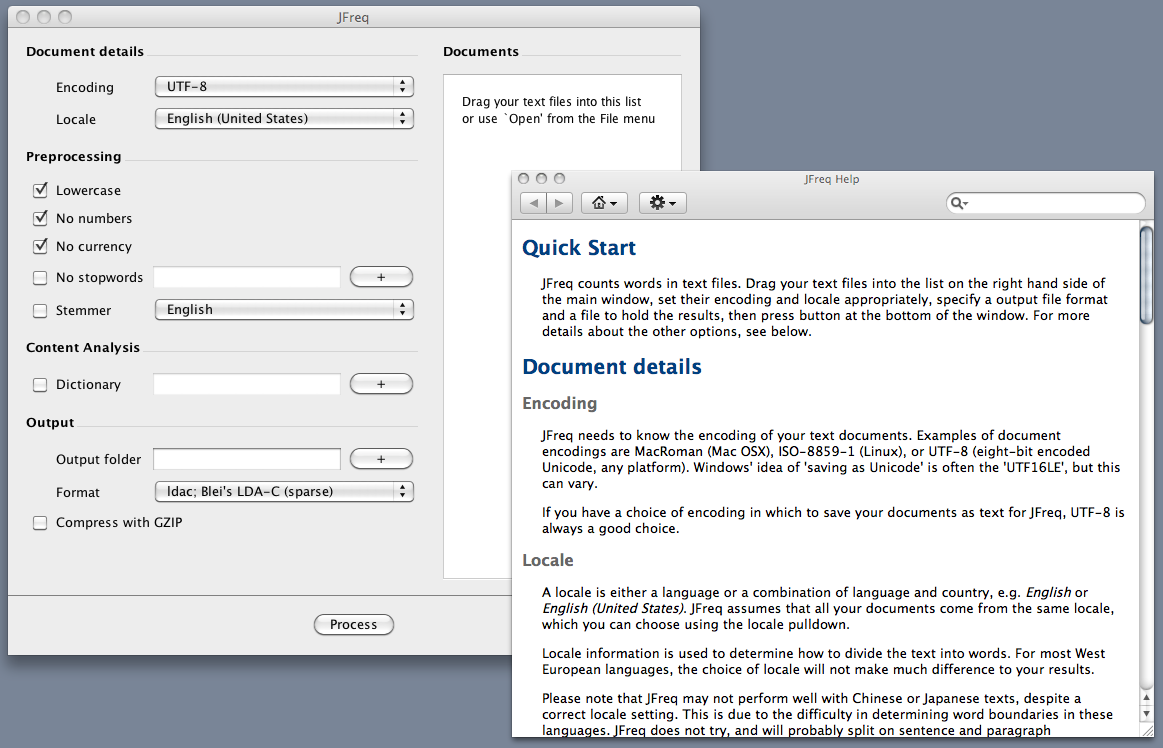
The plain text files can be added directly, or by the folder-load. If folders are offered, JFreq only looks one level down into them for documents and assumes that everything it finds is a plain text file. It is helpful to make sure this is true.
During the counting process JFreq can, optionally
- lowercase everything
- remove currency symbols
- remove digits
- remove stop words with a list you provide
- apply a stemmer for one of 12 European languages
- perform a content analysis with a Yoshikoder dictionary you provide
JFreq output is a folder containing your new word (or category) frequency matrix in a choice of formats, optionally gzipped to save space on your disk. The formats are
-
LDA-C: Blei’s sparse matrix format used for fitting topic models, but quite generally useful for word frequency data. -
MTX: The Matrix Market sparse matrix format used in numerical analysis, in the ‘coordinate integer’ format. -
CSV: Everybody’s first choice of output format. Not well-suited for large scale word-frequency data but reasonable for small document collections and for content analyses
For the MTX and LDA-C formats row labels (filenames) and column labels (word types) are provided alongside the main sparse matrix file in the output folder. There’s also a README to remind you how the format works.
R users may find it useful to know that the ‘lda’ package for topic models (and Blei’s LDA-C software itself) expects files in the LDA-C format and has functions for reading them. Also, the ‘Matrix’ package contains a ‘readMM’ for reading Matrix Market format; just point it at the ‘data.mtx’ file in your output folder.
Download
You can download Version 0.5.4 from Sourceforge. There are also alternative versions available for the command line and for other operating systems, and source code.
License
JFreq is open source software distributed under the Gnu Public License (GPL).
Citation
If you’d like to refer to the package in written work, you can use this:
Lowe W. (2011) ‘JFreq: Count words, quickly’. Java software version 0.5.4, URL: https://conjugateprior.org/software/jfreq/
If you found that useful…
